Representing words in a numerical format has been a challenging and important first step in building any kind of Machine Learning (ML) system for processing natural language, be it for modelling social media sentiment, classifying emails, recognizing names inside documents, or translating sentences into other languages. Machine Learning models can take as input vectors and matrices, but they are unable to directly parse strings. Instead, you need to preprocess your documents, so they can be correctly fed into your ML models. Traditionally, methods like bag-of-words have been very effective in converting sentences or documents into fixed-size matrices. Although effective, they often result in very high-dimensional and sparse vectors. If you want to represent every word in your vocabulary and you have hundreds of thousands of words, you will need many dimensions to fully represent your documents. Instead, what if we numerically represent each word in a document separately and use models specifically designed to process them?
Being able to embed words into meaningful vectors has been one of the most important reasons why Deep Learning has been so successfully applied in the field of Natural Language Processing (NLP). Without the ability to map words like “king”, “man”, or “woman” into a low-dimensional dense vector, models like Recurrent Neural Networks (RNNs) or Transformers might not have been so successful for NLP tasks. In fact, learned embeddings were an important factor in the success of Deep Learning for Neural Machine Translation and Sentiment Analysis, and are still used to these days in models such as BERT.
Word embeddings have been an active area of research, with over 26,000 papers published since 2013. However, a lot of early success in the subject can be attributed to two seminal papers: GloVe (a method that generates vectors based on co-occurrence of words) and word2vec (which learns to predict the context of a word, or a missing word out of a sequence). Whereas both have been used extensively and show great results, a lot of interesting spatial properties were examined for the latter. Not only are similar words like “man” and “woman” close to each other (in terms of cosine distance), but it is also possible to compute arithmetic expressions such as king - man + queen.
Building a Dash app to explore word arithmetic
At Plotly, we have used word embeddings in multiple AI and ML projects and demos, and being able to better understand the arithmetic properties of those methods is important to us. Rather than simply choosing a single nearest neighbor for an expression like king - man + woman or france - paris + tokyo, we wanted to explore the neighborhood of each operation that we are applying to the starting word (i.e. king and france in our case). We felt that Dash was the perfect tool for this, since we were able to leverage powerful Python libraries like NumPy and scikit-learn for directly building a responsive and fully-interactive user interface — all inside a single Python script. As a result, we built a Word Embedding Arithmetic app, which we styled using Dash Enterprise Design Kit and deployed through Dash Enterprise App Manager. For the purpose of this demo, we used a subset of the word2vec embedding trained on the Google News Dataset.
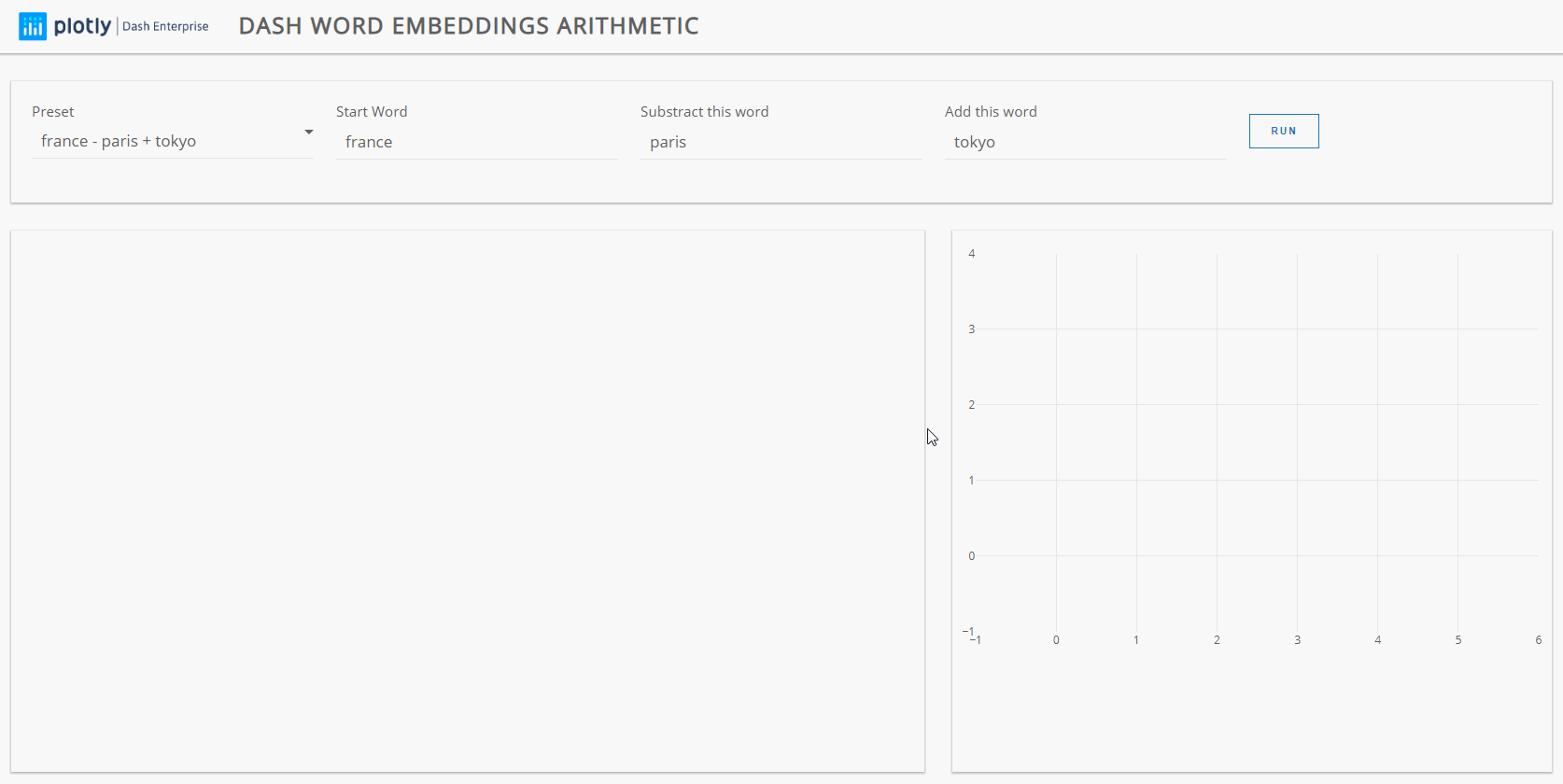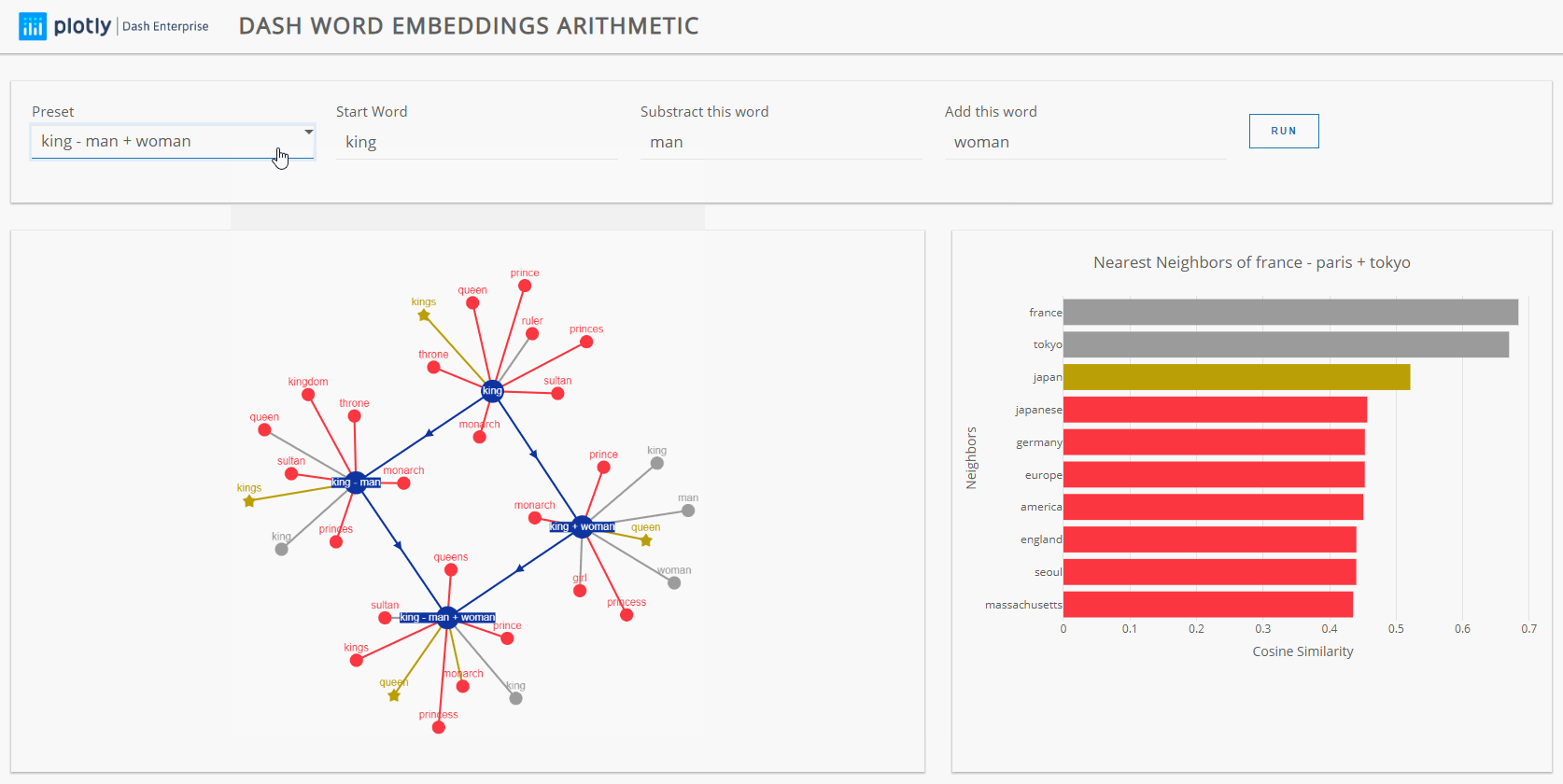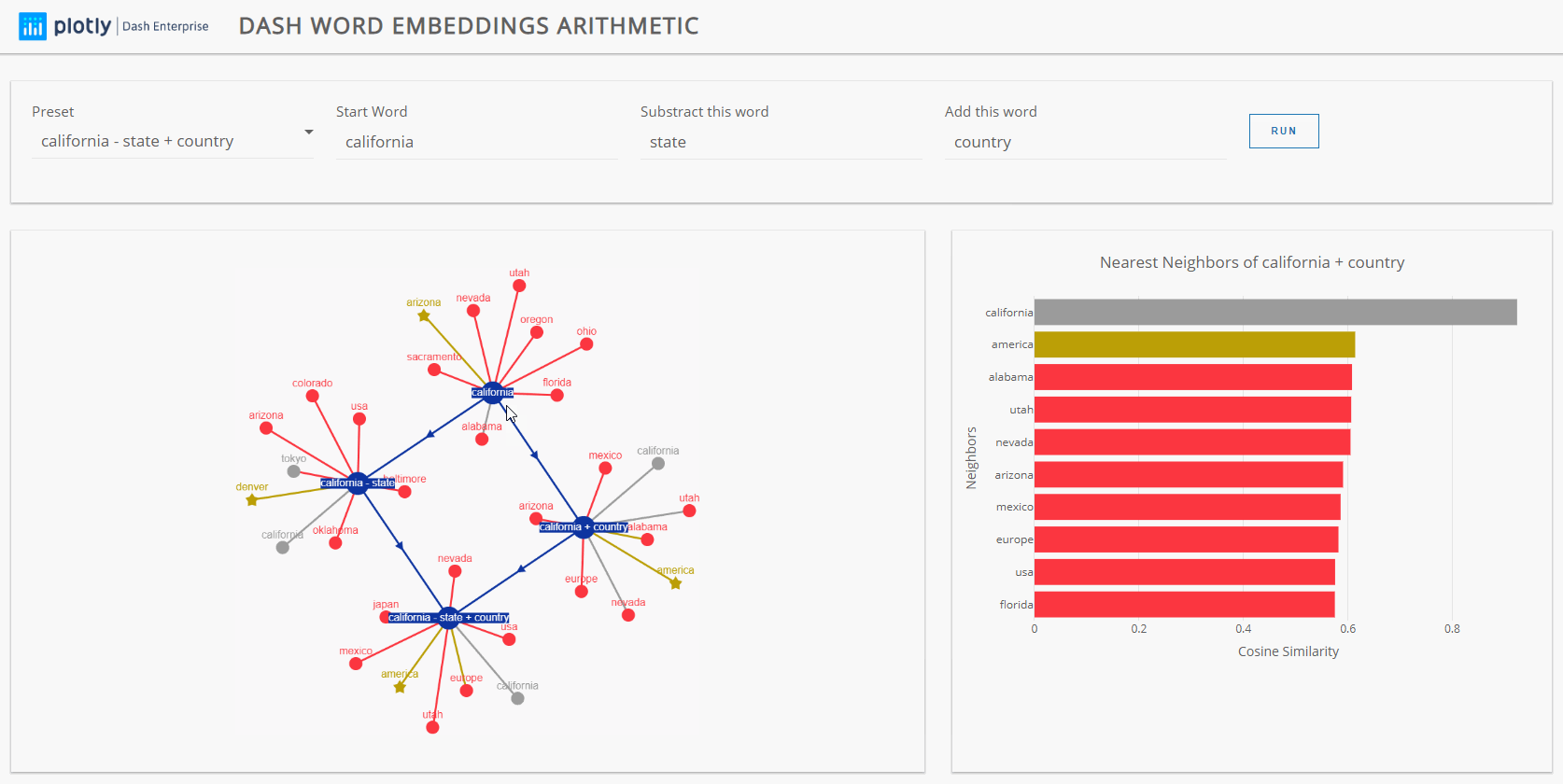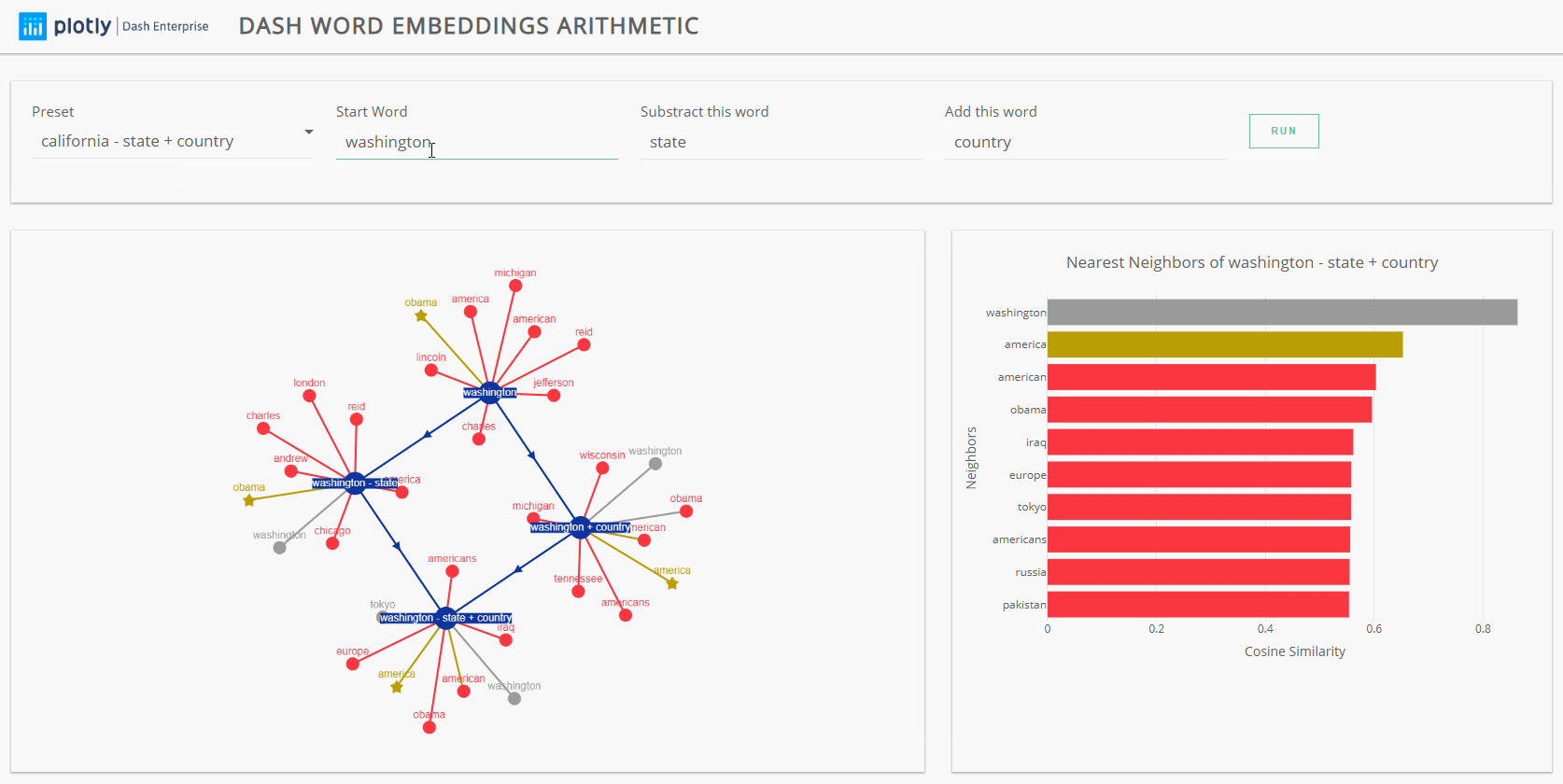
An intuitive way to represent this is to use a network of arithmetic operations, where each operation we are applying to a starting term is connected with a directed edge. For example, for an expression like france - paris + tokyo, we connect the node france to france - paris and france + tokyo, since they are the results of respectively applying subtraction and addition to france. Similarly, we get france - paris + tokyo by applying the same operators to the intermediate nodes. Each of those nodes are colored in blue.

Then, each of those blue nodes (which are themselves vectors) are connected to their 8 nearest neighbors (represented in gray if they appear in the arithmetic expression, and red otherwise).
One important note is that the length of the edges do not depend on the similarity of the neighbors; as a visual distinction, we change the shape of the nearest neighbor (that is not part of the expression) into a star. In addition to this, we made it possible to click on any node in the network to display the similarity of that node to all the nearest neighbors inside a plotly.express bar chart. To create this interaction, you simply need to assign a callback that is fired whenever click a node on a Dash Cytoscape component:
Such callbacks can be written in less than 50 lines of Python code, and result in a highly interactive app:
Why we should be careful about how we construct analogies
Perhaps one of the most famous examples of word2vec arithmetic is the expression king - man + woman = queen, which is technically true, but not as impressive as we would believe. Indeed, in the original paper, the input words (i.e. king, man, woman) are discarded when choosing the nearest neighbor; if they are not discarded, the actual result would be king - man + woman = king. Those ideas are discussed in depth in this blog post.
Another very interesting insight we uncovered is that partial expressions will sometimes yield the same result as the full expression. For example, if we remove the operand man from our expression, we would get king + woman, and the resulting nearest neighbor would still be queen. Similarly, the nearest neighbor for california - state + country and california + country will both be close to america.
Using the Word Arithmetic app, we were able to uncover some pretty interesting results. We first analyzed claims from this highly cited paper that computer_programmer - man + woman will be the closest to homemaker.
computer_programmer” is not available in the subset, we tried using both the expressions “programmer — man + woman” and “homemaker — woman + man”.We found out that, in both cases, the nearest neighbor was actually the start word, and the next nearest neighbor is respectively the plural and the synonym of the words. Of course, the spatial meaning of the word programmer probably differs from computer_programmer, but the meaning of programmer remains similar to words such as animator, engineer, geek and developer.
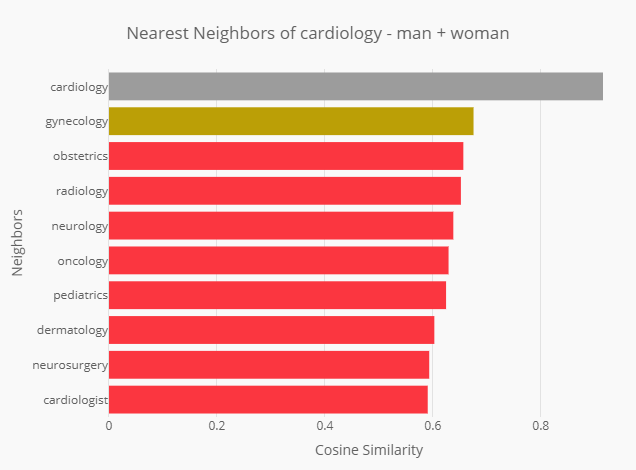
Furthermore, we found that, even for very specialized terms, word embedding exhibits a certain degree of bias. For example, the closest (non-input) neighbor of the expression cardiologist - man + woman was actually gynecologist, closely followed by obstetrics. Such output is pretty interesting, since it is said that 59% of the current gynecologists and 85% of medical residents in obstetrics are women. This likely indicates that the model learned to associate those two specializations with the word woman. If such embeddings were to be applied in a medical setting, they would need to be very carefully evaluated before being deployed, so that such specialized biases can be corrected.
Providing the building blocks for large-scale NLP analysis
In this article, we described an app that lets you explore the most common words from the famous word2vec embedding and walked through useful and interesting relations between various words. However, we are only scratching the surface of what Dash Enterprise is capable of. With our state-of-the-art, scalable application platform running on Kubernetes, you can easily scale machine learning apps to be used by as many users as you want, since Dash is designed with a stateless backend. We believe that providing those building blocks for enterprise-ready AI applications is crucial for moving NLP projects beyond the R&D stage, and we are here to help you achieve this.